HDFS
HDFS 특징
- 분산 파일 시스템 네트워크로 연결된 여러 머신의 스토리지를 관리하는 파일시스템. 특정 노드에 장애가 발생해도 자료가 유실되지 않아야 함. 또한 데이터가 단일 물리 머신의 저장 용량을 초과하게 되면 전체 데이터셋을 분리된 여러 머신에 나눠서 저장할 필요가 있음.
- 일반적으로 매우 큰 파일을 저장 수백 메가바이트 ~ 페타바이트
- 대용량 데이터의 순차적 접근에 유리 첫 번째 레코드를 읽는데 걸리는 지연시간보다, 전체 데이터셋을 모두 읽을 때 걸리는 시간이 더 중요하다.
- 범용 하드웨어를 기반으로 설계 신뢰성이 비교적 낮은, 저가의 범용 하드웨어를 위한 설계. 장애 시 사용자가 알 수 없을 정도의 작업 수행 가능.
- 적합하지 않는 분야
- 빠른 데이터 응답시간이 필요한 경우 / 임의 접근
- 수 많은 작은 파일을 저장해야 할 경우
- 다중 라이터(writer)가 존재 / 파일이 임의 수정이 빈번한 경우
블록
- HDFS 블록 크기는 기본적으로 128MB
- HDFS의 파일은 특정 블록 크기의 청크(chunk)로 쪼개어 저장.
- 블록 크기보다 작은 데이터일 경우 그 크기만큼만 공간 사용.
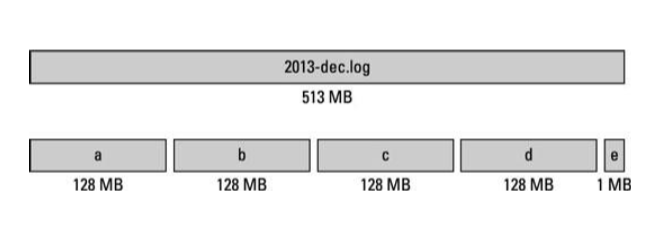
- NTFS 블록 크기(512B ~ 64KB) < HDFS 블록 크기(128MB) 블록이 매우 커, 블록의 시작점 탐색 시간 감소. 탐색 시간을 줄여 데이터 전송 성능 향상. 맵리듀스의 맵 테스크는 한번에 하나의 블록을 처리
- 장애에 대처하기 위한 물리적인 복제에 유리하다.
- 파일 하나의 크기가 단일 디스크의 용량보다 클 수 있다.하나의 파일을 구성하는 여러 개의 블록이 동일한 디스크에만 저장될 필요가 없으므로, 클러스터에 있는 어떤 디스크에도 저장될 수 있다.
HDFS 개념
- 마스터 - 워커 패턴 으로 동작하는 두 종류의 노드로 구성

- Data Node 파일 시스템의 주요 일꾼(worker). 클라이언트나 네임 노드의 요청을 받아 블록들을 송수신하고 저장. 네임 노드에게 블록 리포트를 송신. RAID 같은 데이터 보호장치는 없음.(데이터 복제를 이용)
- Name Node
- 네임스페이스 이미지(파일 시스템 이미지); 파일 시스템 트리와 그 트리에 포함된 모든 파일과 디렉토리에 대한 메타데이터 저장.
- 에디트 로그 (Edit Log)HDFS에 저장된 블록은 기본적으로 수정 불가(덧붙이기 가능). 변경된 내용 에디트 로그에 저장.
- Secondary Node 보조 네임 노드. 에디트 로그가 너무 커지지 않도록 주기적으로 네임스페이스 이미지를 에디트로그와 병합하여, 새로운 네임스페이스 이미지 생성(Checkpointing). 네임노드 머신이 손상될 경우를 대비하여 체크포인트시 네임스페이스 이미지를 보조 네임 노드에 보관한다.
- 블록 캐싱 빈번하게 접근되는 블록은 데이터 노드의 메모리에 캐싱 -> 읽기 성능 향상
- HDFS 페더레이션(Federation) 네임노드의 확장성 문제를 해결한다. 여러 개의 네임 노드가 파일 시스템의 네임 스페이스 일부를 나누어 관리하는 방식.

HDFS 읽기 / 쓰기
- 읽기 작업 ① 클라이언트는 요청한 각 블록의 데이터 노드 리스트를 받음 ② 클라이언트는 요청한 각 블록의 데이터 노드를 선택 ③ 클라이언트는 블록을 연속적으로 읽음

- 쓰기 작업 ① 클라이언트는 네임노드에 작업 의뢰 ② 클라이언트는 특정 노드에 파일을 기록 ③ 데이터 노드는 블록을 복제

- HDFS의 복제 정책
- 복사본을 128MB 단위로 분할(Block), Rack에 분산 저장.
- 복사본 요청 시 네트워크 대역폭 추정, 가까운 복사본 선택.
- 일반적으로 3개의 복사본 유지(같은 랙2개, 다른 랙 1개)
- 서버, 장비 고장 대응 가능 / 접근속도 향상 / 트래픽 분산

HDFS 명령어
| 명령어 | 기능 |
| hadoop fs -cat [경로] | 경로의 파일을 읽어서 보여준다. |
| hadoop fs -count [경로] | 경로상의 디렉토리, 파일, 파일사이즈를 보여준다. |
| hadoop fs -cp [소스 경로] [복사 경로] | HDFS상에서 파일 복사 |
| hadoop fs -ls [소스 경로] | 파일 목록 확인 |
| hadoop fs -rm [소스 경로] | 파일 삭제, 디렉토리는 삭제 안됨 |
| hadoop fs -rmr [소스 경로] | 디렉토리 삭제 |
| hadoop fs -text [소스 경로] | 파일의 정보를 확인하여 텍스트로 반환 |
| hadoop fs -df /user/hadoop | 디스크 공간 확인 |
| hadoop fs -du /user/hadoop | 파일별 사이즈 확인 |
| hadoop fs -dus /user/hadoop | 디렉토리의 사이즈 확인 |
| hadoop fs -mkdir [생성 디렉토리 경로] | 디렉토리 생성 |
| hadoop fs -mkdir -p [생성 디렉토리 경로] | 디렉토리 생성, 부모 경로까지 한번에 생성한다. |
| hadoop fs -put [로컬 경로] [소스 경로] | 리눅스(로컬)의 파일 hdfs상으로 복사 |
| hadoop fs -get [소스 경로] [로컬 경로] | hdfs의 파일 리눅스(로컬)로 다운로드 |
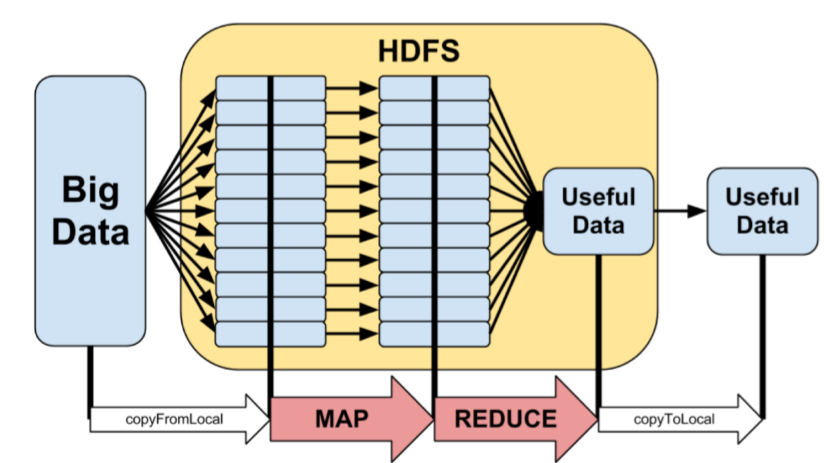
MapReduce
MapReduce
- 분산 병렬 처리를 위한 프레임워크, 프로그래밍 모델.
- 범용 컴퓨터 클러스터(클라우드)에서 수행되는 분산 데이터 처리 모델과 실행 환경 제공
- MapReduce 프레임워크에 맞춰 프로그래밍하고 하둡에서 실행하면 하둡이 자동으로 분산 처리 수행
MapReduce 처리 과정
- Map 데이터를 담아두는 자료구조. 입력데이터를 받아 key-value 형태로 분류한다.
- Reduce Map을 정리, 줄여 나가는 과정.
- MapReduce의 서비스
- Job Tracker 마스터 노드에서 Task Tracker에 작업 할당, 관리. 전체 작업을 관리하는 마스터 역할 수행. Job은 분산처리를 하는 전체 작업을 의미한다.
- Task Tracker Worker Node이며 할당 받은 작업을 데이터 노드가 실행한다. Task는 map 또는 reduce task 1개를 수행하는 작업을 의미한다.

하둡 에코 시스템
- HDFS & MapReduce
- Sqoop RDBMS에 저장된 정형 데이터를 하둡(HDFS)으로 수집하기 위한 도구
- Flume 로그 파일 등 비정형 데이터 수집
- Pig & Hive 비개발자도 HDFS의 데이터를 쉽게 분석할 수 있는 도구
- Mahout 기계학습을 위한 분석 도구
- Oozie MapReduce의 배치처리 작업을 위한 도구
- Ganglia 하둡의 리소스를 모니터링 하기 위한 도구
- ZooKeeper 네임노드의 고장시 고가용성을 유지하기 위한 도구
[참조]
인하공업전문대학 컴퓨터정보과
'Study > clolud' 카테고리의 다른 글
| [클라우드컴퓨팅] 클라우데라 하둡 싱글노드 설치 (2) | 2022.10.14 |
|---|---|
| [클라우드컴퓨팅] 클라우드 서비스 관련 개념 (2) | 2022.09.07 |

